






RAGの仕組みは知ってるけど実装レベルで理解を深めたいと思い、次の記事を参考にさせていただき手を動かしてみました。

目次
前提
- GitHub Codespacesで実施
- Python 3.12がインストール済
- OpenAI APIキー取得済
事前作業
uvインストール
$ curl -LsSf https://astral.sh/uv/install.sh | sh| オプション | 意味 | 何をするか |
|---|---|---|
-L | follow redirects | リダイレクト(302/301など)を自動的に追跡する |
-s | silent | 進捗バーやエラーの詳細を非表示にする(静かに実行) |
-S | show error | -s(サイレント)でも エラー文だけは表示 する |
-f | fail silently | HTTPエラー(404/500など)なら エラーコードで失敗 し、本文を表示しない |
downloading uv 0.9.10 x86_64-unknown-linux-gnu
no checksums to verify
installing to /home/codespace/.local/bin
uv
uvx
everything's installed!ワークディレクトリ作成
$ mkdir simple-rag
$ cd simple-rag
$ uv init
$ ll -atotal 20
drwxrwxrwx+ 2 codespace codespace 4096 Nov 20 14:09 ./
drwxrwxrwx+ 4 codespace root 4096 Nov 20 14:08 ../
-rw-rw-rw- 1 codespace codespace 5 Nov 20 14:09 .python-version
-rw-rw-rw- 1 codespace codespace 0 Nov 20 14:09 README.md
-rw-rw-rw- 1 codespace codespace 88 Nov 20 14:09 main.py
-rw-rw-rw- 1 codespace codespace 156 Nov 20 14:09 pyproject.tomlパッケージをインストール
$ uv add streamlit faiss-cpu python-dotenv openai numpy| ライブラリ名 | 概要 |
|---|---|
| streamlit | Pythonだけで手軽にWebアプリを作れるフレームワーク |
| faiss-cpu | 大量のベクトルから高速に類似検索できるMeta製のベクトル検索エンジン |
| python-dotenv | .env ファイルに書いた環境変数をPythonに読み込む |
| openai | ChatGPTやEmbeddingなど、OpenAI APIをPythonから利用するための公式SDK |
| numpy | 数値計算や行列演算を高速に処理するPythonライブラリ |
Using CPython 3.12.1 interpreter at: /home/codespace/.python/current/bin/python3.12
Creating virtual environment at: .venv
Resolved 54 packages in 400ms
Prepared 52 packages in 2.32s
░░░░░░░░░░░░░░░░░░░░ [0/52] Installing wheels...
...(略)...
+ tzdata==2025.2
+ urllib3==2.5.0
+ watchdog==6.0.0OpenAI APIキーを設定
OPENAI_API_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.envはGitプッシュしないよう、.gitignoreに記述するなど要注意!!
RAG の検索用データ準備
RAG の検索用データとして使用する情報(ベクトル化して登録する情報)をknowledge_source.txtに記述し、dataフォルダへ格納。
日本時間で11月19日(水)のお昼12時から13時にLIVE配信された「超速報!サンフランシスコからお届けする Microsoft Ignite レポート」では、Ignite初日の発表内容の中から印象に残ったトピックや特に注目したい内容を、現地の空気感そのままに爆速で以下の内容が展開されました。
1. イベントのテーマと基盤(Copilotフロントと裏側のガバナンス/セキュリティ): Microsoftの一貫したメッセージは、Copilotをフロントに据え、その裏側でデータアクセス、ガバナンス、セキュリティを重視するという立ち位置が変わっていないことです。ユーザーはCopilot Studioを使ってカスタマイズされたCopilotを利用できる一方で、データアクセス、ガバナンス、およびセキュリティが確保された環境で安心してCopilotを利用できるようになります。
2. 「IQ」フレームワーク(Work IQ、Fabric IQ、Foundry IQなど): 多くの発表を整理するための新しい概念として、「IQ」(Intelligence Quotient)という仕組みが導入されました。ユーザーはMicrosoftのエージェントやデータプラットフォームの能力を、Work IQやFabric IQといった統一された指標や概念で理解しやすくなります。
3. エージェント開発基盤(Microsoft Agent Factoryの登場): エージェント作成のための部品的な要素や機構を提供するフレームワークとして「Microsoft Agent Factory」という名前が登場しました。開発者は、エージェント作成のための統一された部品や機構を利用できるため、エージェントをより効率的に作成できるようになります。
4. Agent 365による管理(エージェントの一括管理製品): 野良エージェントの出現を防ぎ、セキュリティやID管理を含めたエージェントの管理を一括で行うための製品として「Agent 365」が発表されました。IT管理者やテナント管理者は、Microsoft 365だけでなくAzureや他社サービス由来のエージェントも含めてセキュリティやID管理、利用状況を一括で管理できるようになり、野良エージェントの出現による情報漏洩などのリスクを軽減しやすくなります。
5. M365 Copilotの機能強化(Wordのエージェントモード、Outlookのスケジュール調整): M365 Copilotのアップデートとして、Wordの「エージェントモード」が一般提供開始されるほか、Outlookでのスケジュール調整機能など、これまで難しかった機能が一気に追加されました。特に日本人が時間をかけていたWordのフォーマット調整などの作業が「エージェントモード」によって一括で実行可能になり、Outlookでの複雑なスケジュール調整タスクの精度が向上し、煩雑な調整作業から解放されることが期待されます。
6. Anthropicとの協業(LLMの選択肢拡大): Microsoftは、既存のOpenAIとの関係性に加え、Anthropicとの協業を発表しました。ユーザーはCopilot StudioなどでAnthropicのモデルも選択できるようになり、大規模言語モデルの選択肢が広がることで、より目的に合ったAIモデルを選択しやすくなります。
7. Azure Copilotの発表(開発者向けの監視・診断・修正支援): 開発者向けに、Kubernetesなどの環境におけるリソースの監視、エラー診断、および修正コマンドの提案を行う「Azure Copilot」が発表されました。開発者は、AKS環境などでエラーが発生した際、診断から根本原因の特定、さらに修正のためのAZコマンドの提案と承認実行までを支援されるため、問題解決にかかる時間が大幅に短縮されます。
8. Azure Migration Agent(レガシーアプリケーションの移行アセスメント): 既存のレガシーな大規模アプリケーションをAI時代に適合させ、移行先やコストを自動でアセスメントする「Azure Copilot Migration Agent」が登場しました。ユーザーは、レガシーアプリのAI対応への移行計画を策定する際、移行先環境の選択肢(例:PostgreSQL、Managed Redis)や必要な月額コストの自動見積もりを得られるため、移行プロジェクトの計画とコスト管理が容易になります。
9. Power Platformとアプリ開発(自然言語によるアプリ自動作成): Power Platformでは、自然言語での対話を通じて自動的に業務アプリ(例えば人事のタスク管理アプリなど)を作成できる「Copilot in Power Apps」の機能強化が図られました。ユーザーは、コーディングスキルがなくても自然言語で要望を伝えるだけで業務アプリを作成できるようになり、特に小規模なタスク管理やデータ管理アプリの開発手間が劇的に軽減されます。
10. エージェントフレームワークの統合(Semantic KernelとAutoGenの合体): エージェント構築のフレームワークであるSemantic KernelとAutoGenが合体し、「Microsoft Agent Framework」としてFoundry IQと深く連携する形で新しく登場しました。開発者は、ローカルで開発したエージェントをFoundry IQのホスティッドエージェントとして簡単に展開できるようになるため、エージェントの運用・管理の工程がシンプルになります。
11. エージェントのユビキタス化(場所・ツール・接し方を選ばない利用): エージェントは、個人用、チーム用、開発者用など、様々な役割を持ち、場所やツールを選ばず(ユビタス)利用できる方向性が示されました。ユーザーは、音声を含むさまざまな接し方や場所を選ばずに、シームレスにAIアシスタントの支援を受けられるようになります。
12. セキュリティの徹底(プロンプトインジェクションへの対応): エージェントによるプロンプトインジェクションへの対応など、エージェントがデータにアクセスする際のセキュリティやガードレール機能が強化されました。エージェント設定にガードレール機能が追加されることで、ユーザーはプロンプトインジェクションのような悪意のある攻撃のリスクを軽減しつつエージェントを利用できるようになり、不正アクセス時の影響範囲も追跡可能となるため、管理者はセキュリティを維持しやすくなります。RAG実装
最初なので、ここでは安いモデルのgpt-5 nanoで動くことを確認します。
main.py
import os
from pathlib import Path
import numpy as np
import faiss
import streamlit as st
from dotenv import load_dotenv
from openai import OpenAI
# === 設定 ===
EMBEDDING_MODEL = "text-embedding-3-small"
# CHAT_MODEL = "gpt-5" # GPT-5モデル
CHAT_MODEL = "gpt-5-nano" # GPT-5 nanoモデル
TOP_K = 3 # 検索で参照するドキュメント数
# === OpenAIクライアントの初期化 ===
load_dotenv()
try:
# .env の OPENAI_API_KEY を読む
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
except Exception as e:
st.error(f"OpenAI APIキーの読み込みに失敗しました。.envファイルを確認してください。: {e}")
st.stop()
# === ドキュメント読み込み ===
def load_documents(data_dir: str = "data"):
"""
'data'ディレクトリから.txtファイルを読み込む
"""
docs = []
base = Path(data_dir)
if not base.exists():
st.error(f"'{data_dir}' ディレクトリが見つかりません。作成してください。")
return []
for p in base.glob("*.txt"):
try:
text = p.read_text(encoding="utf-8")
docs.append(
{
"id": p.name,
"path": str(p),
"text": text,
}
)
except Exception as e:
st.warning(f"ファイル {p.name} の読み込みに失敗しました: {e}")
return docs
# === 埋め込み生成 ===
def embed_texts(texts):
"""
OpenAIの埋め込みAPIを利用して、テキストリストをベクトル化
"""
try:
resp = client.embeddings.create(
model=EMBEDDING_MODEL,
input=texts,
)
embeddings = [d.embedding for d in resp.data]
return np.array(embeddings, dtype="float32")
except Exception as e:
st.error(f"Embeddingの生成に失敗しました: {e}")
return None
# === ベクトルインデックスの構築 ===
@st.cache_resource(show_spinner="ドキュメントをベクトル化しています...")
def build_index():
"""
ドキュメントを読み込み、ベクトル化し、Faissインデックスを構築する
"""
docs = load_documents()
if not docs:
st.error("data/ 配下に .txt ファイルがありません。RAGの検索対象となるファイルを追加してください。")
st.stop()
texts = [d["text"] for d in docs]
embeddings = embed_texts(texts)
if embeddings is None:
st.error("Embeddingの生成に失敗したため、インデックスを構築できません。")
st.stop()
dim = embeddings.shape[1]
index = faiss.IndexFlatL2(dim) # L2距離(ユークリッド距離)
index.add(embeddings)
return index, embeddings, docs
# === 検索(Retrieval) ===
def search_similar_docs(query: str, index, docs, k: int = TOP_K):
"""
質問文をベクトル化し、Faissで類似ドキュメントを検索する
"""
query_emb = embed_texts([query]) # shape: (1, dim)
if query_emb is None:
return []
distances, indices = index.search(query_emb, k)
results = []
for dist, idx in zip(distances[0], indices[0]):
doc = docs[int(idx)]
results.append(
{
"score": float(dist),
"doc_id": doc["id"],
"path": doc["path"],
"text": doc["text"],
}
)
return results
# === プロンプト組み立て ===
def build_rag_prompt(question: str, retrieved_docs):
"""
検索結果と質問文を組み合わせて、LLMへのプロンプトを作成する
"""
# コンテキストとして使うテキスト(長すぎるときは適当に切る)
max_chars = 1000
context_parts = []
for r in retrieved_docs:
t = r["text"]
if len(t) > max_chars:
t = t[:max_chars] + "\n...(以下略)"
context_parts.append(f"[{r['doc_id']}]\n{t}")
context = "\n\n---\n\n".join(context_parts)
system_prompt = (
"あなたは社内ドキュメントに基づいて回答するアシスタントです。"
"コンテキストに書かれていないことは推測せず、「分かりません」と答えてください。"
)
user_prompt = f"""以下は社内ドキュメントから抽出したコンテキストです。
# コンテキスト
{context}
---
# ユーザーからの質問
{question}
---
上記コンテキストの内容だけを根拠に、日本語で丁寧に回答してください。
コンテキストに十分な情報がない場合は、その旨を正直に伝えてください。
"""
return system_prompt, user_prompt
# === 回答生成(Generation) ===
def generate_answer(system_prompt: str, user_prompt: str):
"""
OpenAI Responses APIを叩いて回答を生成する
"""
try:
resp = client.responses.create(
model=CHAT_MODEL,
instructions=system_prompt,
input=user_prompt,
# GPT-5は temperature 固定なので指定しない
)
# すべてのテキスト出力が一つにまとまったプロパティ
return resp.output_text
except Exception as e:
st.error(f"OpenAI APIの呼び出しに失敗しました: {e}")
return None
# === Streamlit UI ===
def main():
st.set_page_config(page_title="RAGをゼロから実装する【2025年版】", layout="wide")
st.title("RAGをゼロから実装して仕組みを学ぶ【2025年版】")
st.caption(f"モデル: {CHAT_MODEL} | Embedding: {EMBEDDING_MODEL} | 検索: Faiss")
st.write(
f"このデモでは、ローカルの `{Path('data').resolve()}` フォルダ内にある `.txt` ドキュメントを検索対象にした、シンプルなRAGを実装しています。"
)
# インデックス構築
try:
index, embeddings, docs = build_index()
except Exception as e:
st.error(f"インデックスの構築に失敗しました。: {e}")
st.stop()
with st.sidebar:
st.header("設定")
top_k = st.slider("参照するドキュメント数", 1, 10, TOP_K)
st.markdown("### 読み込まれたドキュメント一覧")
if docs:
for d in docs:
st.markdown(f"- `{d['id']}`")
else:
st.warning("ドキュメントがありません。")
question = st.text_input("質問を入力してください(例:ナレッジセンスとは?)")
run = st.button("RAGに聞いてみる")
if run and question:
with st.spinner("検索 & 回答生成中..."):
# 1. 検索
retrieved = search_similar_docs(question, index, docs, k=top_k)
if not retrieved:
st.error("検索に失敗しました。")
st.stop()
# 2. プロンプト作成
system_prompt, user_prompt = build_rag_prompt(question, retrieved)
# 3. 回答生成
answer = generate_answer(system_prompt, user_prompt)
if answer:
col1, col2 = st.columns(2)
with col1:
st.subheader("🤖 回答")
st.write(answer)
with col2:
st.subheader("📚 検索されたコンテキスト")
for r in retrieved:
with st.expander(f"`{r['doc_id']}`(類似スコア: {r['score']:.4f})"):
st.text(r["text"][:1500]) # 表示しすぎると重いので適当に切る
else:
st.error("回答の生成に失敗しました。")
elif run and not question:
st.warning("質問を入力してください。")
if __name__ == "__main__":
main().envから API キー読み込み & OpenAI クライアント作成data/フォルダ内の.txtを全部読み込む- それらのテキストを 埋め込みベクトルに変換 → Faiss インデックス構築
- ユーザーが質問を入力してボタンを押す
- 質問を埋め込みに変換して、Faiss で 似ている文書を検索
- 検索で取れた文書+質問文から RAG 用プロンプトを組み立てる
- GPT-5 nano(
gpt-5-nano)に投げて 回答生成 - 画面左に「回答」、右に「参照されたコンテキスト」を表示
実行
$ uv run streamlit run main.py...(略)...
Local URL: http://localhost:8501
...(略)...http://localhost:8501をクリックするとブラウザに画面が表示されます。
質問を入力して送信してみます。
期待する回答が返って来ました!
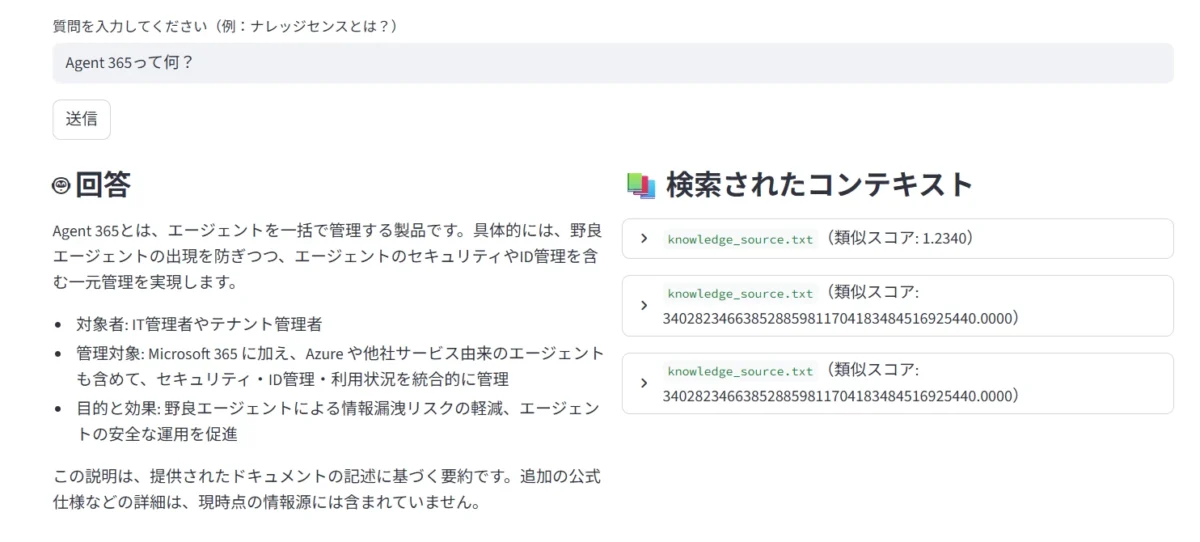
右側にスコアも表示してくれているのも嬉しい。
まとめ
冒頭の記事を参考にさせていただいたおかげで、LLMのコストだけで済むシンプルなRAGを実装して動きを確認できました。
AzureやAWSなどのサービスを使うと楽に構築できますがブラックボックスになりがちなので、中の仕組みを把握するのはトラブルシュートする際も大切です。
これを機に、RAGの精度を高める方法や評価方法も学んでいけたらと思います。